
經過20多年的發展,寶德持續而深刻地把握市場需求,積累了海量的客戶資源和豐富的服務經驗

在過去幾年,全球的數據量以每年58%的速度快速增長,類型也不斷豐富,模型訓練擁有海量的優質樣本,但更大的挑戰來自于算法和硬件計算架構,為此,寶德服務器提出了基于深度卷積神經網絡的圖像識別軟硬件一體化解決方案。
圖像識別指用視覺傳感器(攝像頭)和計算機來模擬人眼和大腦,進行物體識別、跟蹤和測量,進而做圖形處理讓計算機理解真實世界。圖像識別技術有很多應用場景,如:人臉識別、拍照識別、物體識別等各種圖像場景的識別。基于深度學習的圖像識別技術發展痛點用來訓練識別模型的樣本數據不足訓練圖像識別模型,需大量的樣本數據多次迭代訓練,數據須具有識別對象的基本特征,有不同的背景角度區分,數據樣本越豐富,模型的識別精度越高。數據量積累不足,使得模型精準度往往不高。
圖像識別算法不夠先進圖像識別從最初的特征值抓取,發展到模式識別的邊緣濾波,形態學檢測經歷了20年。現在主要停留在淺層訓練的機器學習階段,盡管模型可實現機器替代人,但算法無法自行迭代學習,僅算是樣本訓練的智能程序。
計算機集群性能不夠,計算用時太長算法執行需硬件架構的支撐,一個模型對海量的樣本數據進行學習,在CPU上執行一般需幾天甚至幾個月,大大拉長了研發周期和拖慢產品進程。因此,先進的硬件計算架構是激活優秀算法的前提。

圖像識別指用視覺傳感器(攝像頭)和計算機來模擬人眼和大腦,進行物體識別、跟蹤和測量,進而做圖形處理讓計算機理解真實世界。圖像識別技術有很多應用場景,如:人臉識別、拍照識別、物體識別等各種圖像場景的識別。基于深度學習的圖像識別技術發展痛點用來訓練識別模型的樣本數據不足訓練圖像識別模型,需大量的樣本數據多次迭代訓練,數據須具有識別對象的基本特征,有不同的背景角度區分,數據樣本越豐富,模型的識別精度越高。數據量積累不足,使得模型精準度往往不高。
圖像識別算法不夠先進圖像識別從最初的特征值抓取,發展到模式識別的邊緣濾波,形態學檢測經歷了20年。現在主要停留在淺層訓練的機器學習階段,盡管模型可實現機器替代人,但算法無法自行迭代學習,僅算是樣本訓練的智能程序。
計算機集群性能不夠,計算用時太長算法執行需硬件架構的支撐,一個模型對海量的樣本數據進行學習,在CPU上執行一般需幾天甚至幾個月,大大拉長了研發周期和拖慢產品進程。因此,先進的硬件計算架構是激活優秀算法的前提。
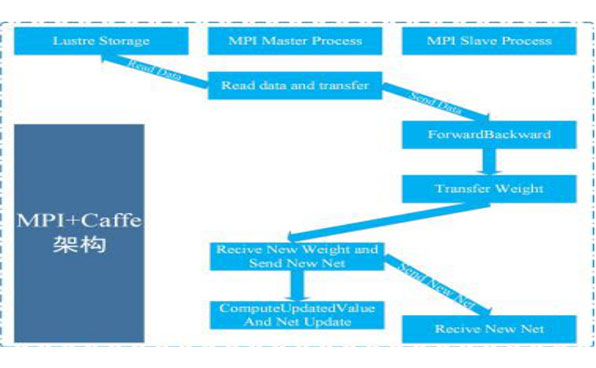
基于深度學習的圖像識別的軟件解決方案
軟件架構:MPI+Caffe
深度卷積神經網絡(CNN)算法是深度學習領域普遍采用的神經網絡構建模型,Caffe是目前最快的CNN架構。寶德的基于Intel集群版Caffe計算框架正是切中當下深度學習的迫切需求,它采用MPI技術對Caffe版本進行數據并行優化,該框架基于伯克利caffe架構進行開發,完全保留原始caffe架構的特性。即:純粹的C++/CUDA架構,支持命令行、Python和MATLAB接口等多種編程方式,具備上手快、速度快、模塊化、開放性等眾多特性,為用戶提供了最佳的應用體驗。另外,鑒于眾多用戶基于CPU進行深度學習應用研究的現實,還可提供C-G算法遷移增值服務,針對用戶目前的深度學習算法,做硬件適配性算法遷移和升級優化,幫助用戶做到算法的更快,更好。硬件架構:IB網絡+GPU集群+Lustre并行存儲

寶德服務器

寶德自強












 4008-870-872
4008-870-872
